My work on Artificial General Intelligence (AGI) safety
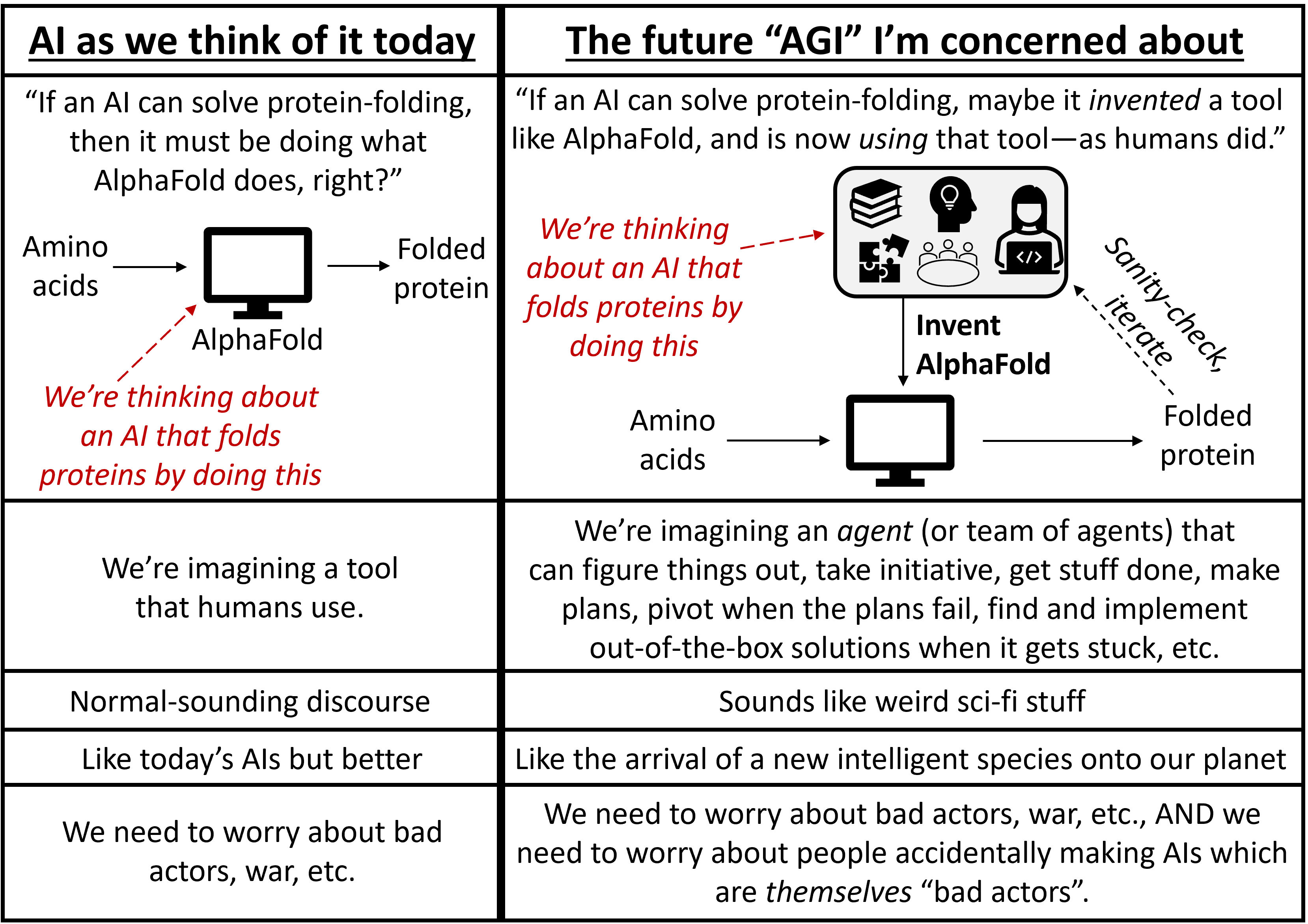
At some point, we will invent "Artificial General Intelligence" (AGI): AI that can reason, learn, understand, and creatively solve problems across a wide range of domains, just as the most competent humans (and teams of humans, and societies of humans) can.
An emerging, interdisciplinary subfield of computer science, called AGI safety or AI alignment, is aimed at developing methods to ensure that these very powerful systems will robustly behave in ways we want them to behave, avoid catastrophic accidents, and make the world a better place. For a nice introduction to the field, I suggest the “Preventing an AI-Related Catastrophe” problem profile by Benjamin Hilton, or my own introductory post.
I've been studying this topic since 2019—first in my free time, then under grant funding†, and now at the nonprofit Astera Institute.
Some highlights of my work are below, and you can keep up with new posts via RSS feed, Twitter, Mastodon, or Threads.
1. Brain-Like-AGI Safety: If we invent AGI by reverse-engineering (or reinventing) algorithms similar to the human brain’s, then how would we use such an AGI safely?
"Intro to Brain-Like-AGI Safety" blog post series: (Jan–May 2022)
• 1. What's the problem & Why work on it now?
• 2. “Learning from scratch” in the brain
• 3. Two subsystems: Learning & Steering
• 4. The “short-term predictor”
• 5. The “long-term predictor”, and TD learning
• 6. Big picture of motivation, decision-making, and RL
• 7. From hardcoded drives to foresighted plans: A worked example
• 8. Takeaways from neuro 1/2: On AGI development
• 9. Takeaways from neuro 2/2: On AGI motivation
• 10. The alignment problem
• 11. Safety ≠ alignment (but they’re close!)
• 12. Two paths forward: “Controlled AGI” and “Social-instinct AGI”
• 13. Symbol grounding & human social instincts
• 14. Controlled AGI
• 15. Conclusion: Open problems, how to help, AMA
Other posts on Brain-Like-AGI Safety, in reverse chronological order:
• Response to Dileep George: AGI safety warrants planning ahead (July 2024)
• Thoughts on “AI is easy to control” by Pope & Belrose (Dec 2023)
• 8 examples informing my pessimism on uploading without reverse engineering (Nov 2023)
• LeCun’s “A Path Towards Autonomous Machine Intelligence” has an unsolved technical alignment problem (May 2023)
• Connectomics seems great from an AI x-risk perspective (Apr 2023)
• EAI Alignment Speaker Series #1: Challenges for Safe & Beneficial Brain-Like Artificial General Intelligence with Steve Byrnes (March 2023)
• Plan for mediocre alignment of brain-like [model-based RL] AGI (March 2023)
• Why I’m not working on {debate, RRM, ELK, natural abstractions} (Feb 2023)
• Heritability, Behaviorism, and Within-Lifetime RL (Feb 2023)
• Thoughts on hardware / compute requirements for AGI (Jan 2023)
• Note on algorithms with multiple trained components (Dec 2022)
• My AGI safety research—2022 review, ’23 plans (Dec 2022)
• My take on Jacob Cannell’s take on AGI safety (Nov 2022)
• I was interviewed on the “Brain Inspired” podcast (Oct 2022)
• Thoughts on AGI consciousness / sentience (Sept 2022)
• Response to Blake Richards: AGI, generality, alignment, & loss functions (July 2022)
• Consequentialism & corrigibility (Dec 2021)
• Brain-inspired AGI and the "lifetime anchor" (Sept 2021)
• Randal Koene on brain understanding before whole brain emulation (Aug 2021)
• Dopamine-supervised learning in mammals & fruit flies (Aug 2021)
• Research agenda update (Aug 2021)
• Value loading in the human brain: a worked example (Aug 2021)
• A model of decision-making in the brain (the short version) (July 2021)
• Model-based RL, desires, brains, wireheading (July 2021)
• (Brainstem, Neocortex) ≠ (Base Motivations, Honorable Motivations) (July 2021)
• Reward is not enough (June 2021)
• Big picture of phasic dopamine (see also: supplementary information) (June 2021)
• Solving the whole AGI control problem, version 0.0001 (Apr 2021)
• My AGI threat model: misaligned model-based RL agent (March 2021)
• Against evolution as an analogy for how humans will create AGI (March 2021)
• Comments on "The singularity is nowhere near" (March 2021)
• Is RL involved in sensory processing? (March 2021)
• Book review: A Thousand Brains by Jeff Hawkins (March 2021)
• Multi-dimensional rewards for AI interpretability and control (Jan 2021)
• Conservatism in neocortex-like AGIs (Dec 2020)
• Inner alignment in salt-starved rats (Nov 2020)
• Supervised learning of outputs in the brain (Oct 2020)
• "Little glimpses of empathy" as the foundation for social emotions (Oct 2020)
• My computational framework for the brain (Sept 2020)
• Emotional valence vs RL reward: a video game analogy (Sept 2020)
• Can you get AGI from a Transformer? (July 2020)
• Mesa-Optimizers vs “Steered Optimizers” (July 2020)
• Gary Marcus vs Cortical Uniformity (June 2020)
• Building brain-inspired AGI is infinitely easier than understanding the brain (June 2020)
• Inner alignment in the brain (Apr 2020)
• Book review: Rethinking Consciousness (Jan 2020)
• Predictive coding = RL + SL + Bayes + MPC (Dec 2019)
• Human instincts, symbol grounding, and the blank-slate neocortex (Oct 2019)
• Jeff Hawkins on neuromorphic AGI within 20 years (July 2019)
2. Non-neuroscience AGI safety posts (technical)
• Four visions of Transformative AI success (Jan 2024)
• Deceptive AI ≠ Deceptively-aligned AI (Jan 2024)
• Thoughts on “Process-Based Supervision” (July 2023)
• The No Free Lunch theorem for dummies (Dec 2022)
• My take on Vanessa Kosoy's take on AGI safety (Sept 2021)
• Thoughts on safety in predictive learning (June 2021)
• Three mental images from thinking about AGI debate and corrigibility (Aug 2020)
• Thoughts on implementing corrigible robust alignment (Nov 2019)
• Self-supervised learning and AGI safety (Aug 2019)
• Self-supervised learning and manipulative predictions (Aug 2019)
• The self-unaware AI oracle (July 2019)
3. Non-neuroscience AGI safety posts (less technical)
• Response to nostalgebraist: proudly waving my moral-antirealist battle flag (May 2024)
• “Artificial General Intelligence”: an extremely brief FAQ (March 2024)
• “X distracts from Y” as a thinly-disguised fight over group status / politics (Sept 2023)
• Munk AI debate: confusions and possible cruxes (June 2023)
• AI doom from an LLM-plateau-ist perspective (Apr 2023)
• “Endgame safety” for AGI (Jan 2023)
• What does it take to defend the world against out-of-control AGIs? (Oct 2022)
• Let's buy out Cyc, for use in AGI interpretability systems? (Dec 2021)
• Safety-capabilities tradeoff dials are inevitable in AGI (Oct 2021)
• On unfixably unsafe AGI architectures (Feb 2020)
• Thoughts on Robin Hanson's AI Impacts interview (Nov 2019)
• In defense of Oracle ("Tool") AI research (Aug 2019)
• 1hr talk: Intro to AGI safety (June 2019)
4. More posts about neuroscience—these mostly aren’t superficially related to AGI safety, but they still came up during my research
• Incentive Learning vs Dead Sea Salt Experiment (June 2024)
• (Appetitive, Consummatory) ≈ (RL, reflex) (June 2024)
• Spatial attention as a “tell” for empathetic simulation? (Apr 2024)
• Woods’ new preprint on object permanence (March 2024)
• Social status part 2/2: everything else (March 2024)
• Social status part 1/2: negotiations over object-level preferences (March 2024)
• “Valence series” Appendix A: Hedonic tone / (dis)pleasure / (dis)liking (Dec 2023)
• “Valence series” part 5: “Valence Disorders” in Mental Health & Personality (Dec 2023)
• “Valence series” part 4: Valence & Liking / Admiring (June 2024)
• “Valence series” part 3: Valence & Beliefs (Dec 2023)
• “Valence series” part 2: Valence & Normativity (Dec 2023)
• “Valence series” part 1: Introduction (Dec 2023)
• I’m confused about innate smell neuroanatomy (Nov 2023)
• A Theory of Laughter—Follow-up (Sept 2023)
• A Theory of Laughter (Aug 2023)
• Model of psychosis, take 2 (Aug 2023)
• Lisa Feldman Barrett versus Paul Ekman on facial expressions & basic emotions (July 2023)
• Is “FOXP2 speech & language disorder” really “FOXP2 forebrain fine-motor crappiness”? (March 2023)
• Why I’m not into the Free Energy Principle (March 2023)
• Schizophrenia as a deficiency in long-range cortex-to-cortex communication (Feb 2023)
• Quick notes on “mirror neurons” (Oct 2022)
• Book review: “The Heart of the Brain: The Hypothalamus and Its Hormones” (Sept 2022)
• On oxytocin-sensitive neurons in auditory cortex (Sept 2022)
• I’m mildly skeptical that blindness prevents schizophrenia (Aug 2022)
• The “mind-body vicious cycle” model of RSI & back pain (June 2022)
• The Intense World Theory of Autism (Sept 2021)
• Neuroscience things that confuse me right now (July 2021)
• How is low-latency phasic dopamine so fast? (July 2021)
• Book review: Feeling Great by David Burns (June 2021)
• Acetylcholine = Learning rate (aka plasticity) (March 2021)
• Late-talking kids and "Einstein syndrome" (Feb 2021)
• Supervised learning in the brain, part 4: compression / filtering (Dec 2020)
• Predictive coding and motor control (Feb 2020)
• Predictive coding and depression (Jan 2020)
† My work from March 2021 through Aug 2022 was funded by a grant from Beth Barnes and the Centre For Effective Altruism Donor Lottery Program.